Como logré monitorizar mi servidor
hace 1 año | 5 min read
¿Te imaginas descubrir un problema en tu servidor justo a tiempo antes de que falle? Esto es posible si estás monitorizando y recolentando datos de uso de tu servidor, para lograr esto existe Prometheus el cual es una herramienta de monitoreo y de alerta de código abierto.
No recuerdo exactamente cuándo conocí Prometheus, pero desde entonces siempre estaba en mi mente y quería implementarlo en mi servidor, como actualmente no tengo ningún proceso o aplicación crítico corriendo no le di mucha prioridad, pero ya era hora de aprender a instalar esta herramienta para usarla en algún ambiente de producción que es donde realmente es importante.
¿Qué harías si ocurre una caída en tu servidor? La respuesta es sencilla, sería buscar el problema para luego tomar acción y resolver este problema para que no vuelva a ocurrir. Pero si no tienes información es difícil llegar al problema y tienes que usar tus conocimientos acerca de los procesos que se están ejecutando y entender cuál podría haber fallado. Pero si hay información de los datos de uso del servidor entonces podría ayudar a encontrar la solución.
Imagina que de forma repentina, tu servidor comienza a experimentar picos de carga alrededor de la medianoche. Sin datos de monitorización, tendrías que adivinar si se trata de un aumento de tráfico, un fallo en algún proceso o incluso un ataque. Sin embargo, si cuentas con información detallada (gracias a Prometheus), podrías descubrir que a esa hora se ejecuta un script de mantenimiento que consume gran parte de la CPU y la memoria. La solución sería reprogramar este script para que se ejecute en un momento de menor carga y ajustar la configuración del servidor para garantizar que el proceso de mantenimiento no afecte a los servicios críticos. De esta manera, no solo resuelves el problema, sino que además previenes futuras caídas y optimizas el rendimiento general de tu sistema.
¿Cómo empecé a monitorizar mi servidor?
Gracias a que aprendí Docker, ahora disfruto de los beneficios de este, cuando decidí instalar Prometheus lo primero que hice fue buscar la instalación con un contenedor de Docker en la documentación.
Creé un archivo de configuración de prometheus que contiene lo siguiente (/etc/prometheus/prometheus.yml):
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
Este archivo lo que hace realmente es que monitoriza el propio contenedor de Prometheus, lo cual no es muy práctico. Pero como estaba empezando solo me interesaba que funcionase.
Luego tuve que agregar el servicio a mi docker-compose.yml, así quedó el servicio (ocultaré los labels de los servicios porque no los quiero publicar):
prometheus:
image: prom/prometheus
container_name: prometheus
networks:
- net
volumes:
- prometheus-data:/prometheus
- /etc/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
deploy:
resources:
limits:
cpus: '2.0'
memory: 600M
Cuando vi que el contenedor está funcionando sin problemas, entré a ver qué contenía y vi que la información no era muy útil, primeramente por lo que comenté anteriormente de que se monitoriza a sí mismo, pero aparte de eso vi que para leer la información había que hacerle querys a prometheus, por lo tanto recolecta y guarda información pero no la muestra de una forma práctica.
Por lo tanto busqué en Youtube algún tutorial a ver cuál era el uso que le daban a esta herramienta, conseguí este video el cual me fue útil porque usaba prometheus con Docker al igual que otro servicio que se requiere el cual es Grafana, hay otro servicio necesario pero en el tutorial lo instaló directamente en el servidor, a diferencia del tutorial yo usaré su imagen de Docker para facilitar el proceso.
Cuando instalé Grafana e intenté acceder al panel, me apareció un error:

Mi problema, como dice el punto 1 de la imagen, era que estaba usando un reverse proxy y esto traía conflictos para servir contenidos estáticos. Entonces como indica en la imagen sabía que tenía que configurar alguna variable de entorno, lo primero que hice fue entrar en la página de la imagen de Grafana de Docker hub, pero no encontré lo que estaba buscando, después de una búsqueda no recuerdo exactamente cómo lo conseguí, vi esta sección en la documentación de Grafana, por lo tanto simplemente agregué GF_SERVER_ROOT_URL y GF_SERVER_SERVE_FROM_SUB_PATH al servicio de Grafana.
Para Grafana mi servicio quedó así:
grafana:
image: grafana/grafana
container_name: grafana
volumes:
- grafana-data:/var/lib/grafana
networks:
- net
environment:
- GF_SERVER_ROOT_URL=https://mi-url.com/ #Esto es un placeholder para el post
- GF_SERVER_SERVE_FROM_SUB_PATH=true
Por último busqué cómo implementar en un contenedor lo último que me faltaba para recoletar la información que quería, que es el node exporter, así quedó el servicio:
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
networks:
- net
Y también tuve que actualizar el archivo de prometheus.yml para que éste empezara a tomar los datos del contenedor de node exporter, lo que hice fue que agregué el job en la sección de scrape_configs:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'prometheus'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['node-exporter:9100']
Esta archivo establece la frecuencia global de adquisición de métricas (15 segundos). Además, se definen dos “jobs”: uno para que Prometheus se monitorice a sí mismo (con un scrape_interval más corto de 5 segundos) y otro para recopilar métricas del node_exporter (en el puerto 9100). Así, Prometheus sabrá cada cuánto tiempo y desde dónde extraer las métricas de tu servidor.
Por último, tuve que configurar el origen de datos, para esto simplemente accedí a la opción de la interfaz de Grafana, seleccioné Prometheus y configuré lo que me pedía. Con el dashboard hice lo mismo, todo este proceso está explicado en el video que vi.
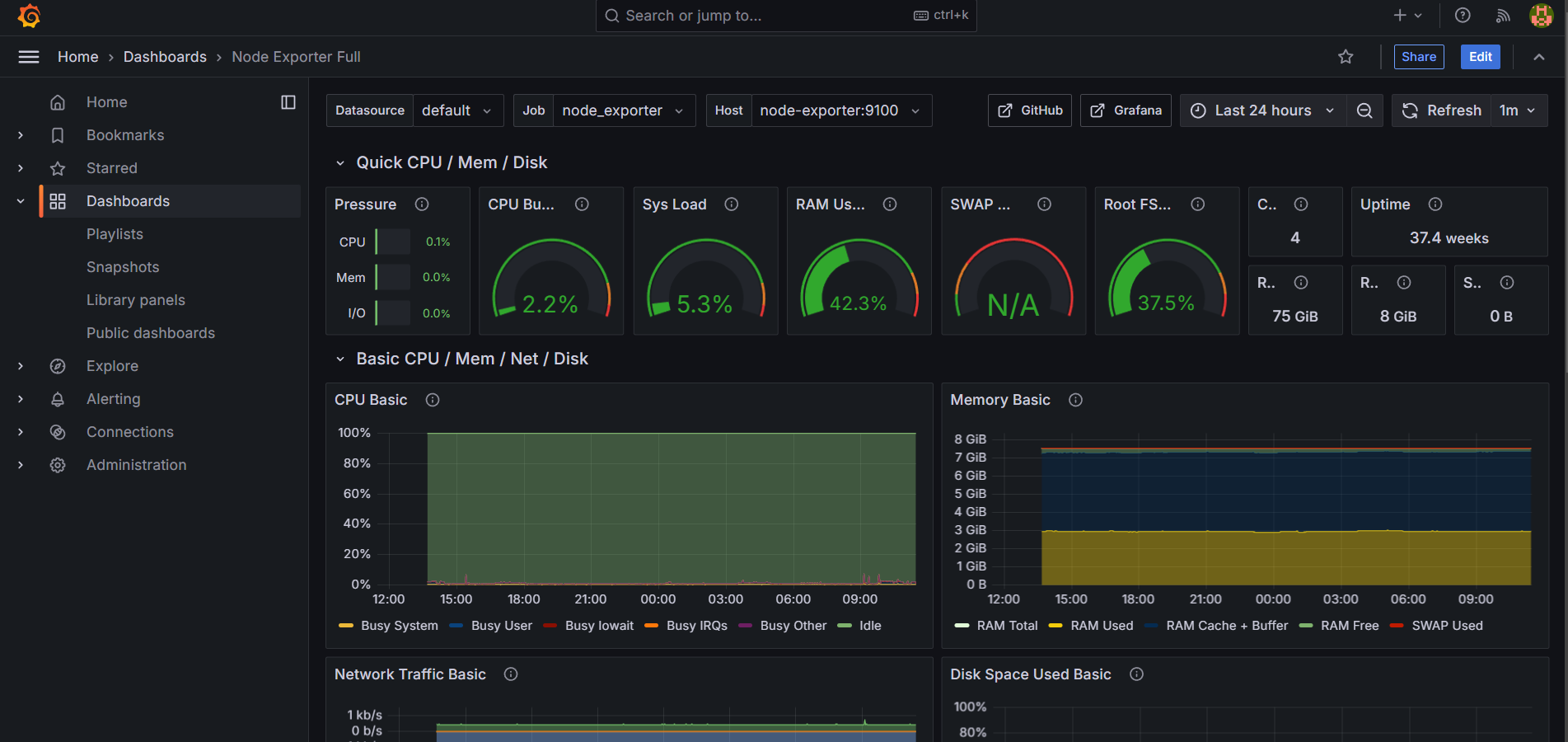
Este es el resultado de todo: